
When you are constructing your data warehouse you will likely encounter data from multiple data sources, some of which have data in undesirable formats. For example, some database tables might be populated from Excel sheets that weren’t exactly designed to fit cleanly into a table, much less a data warehouse table. A budgeting Excel sheet that needs to be imported may look something like this:
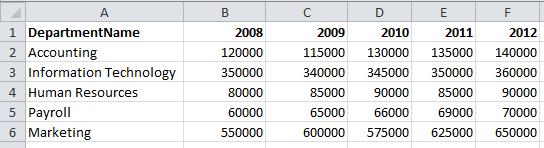
This budget data will display as an identical table and structure if no transformations are made during the import. As you can see, this is not an extensible design and it definitely doesn’t belong in a data warehouse without some alterations. As the budget years are added the ETL process will need to be changed to handle the new columns. This will also grow the table to an unmanageable size over a period of many years.
An easy solution to this dilemma is to use the UNPIVOT function to restructure the data and organize it in a manner that can be used in your data warehouse. After you have extracted the data in this budget Excel sheet into a staging table you will be able to reorganize it. Using our basic table example the UNPIVOT function would be:
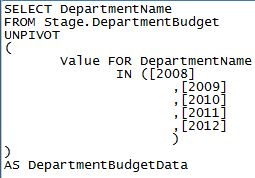
The PIVOT function will take the rows in a table and pivot them into columns. So intuitively, the UNPIVOT function will do the opposite; it takes the columns in a table and pivots them into rows. After running the above UNPIVOT function your data set will become:
This seems easy enough, but remember each column that is to be pivoted into a row must have matching data types and sizes. When your data types and sizes don’t match exactly you must first convert all of your columns in your select statement to have a matching data type before running the UNPIVOT function. Mismatched data types could be the result of the source data being incorrectly assigned inconsistent data types. The easiest way that I have found to accomplish this is to first use a common table expression (CTE) to convert the data and then use your CTE as the source for your selection in your UNPIVOT function.
Using the above example let’s assume that the 2012 data is a varchar(25) and the other yearly data is a float data type. The new UNPIVOT script would look like:

This method is easy to read and understand, so for coding clarity I like to use it. I’m sure there are multiple ways to solve this type of issue so please feel free to comment and share any other ways that you have found that work well for you.
I hope this has been helpful, have a great day!







